
About SimDB
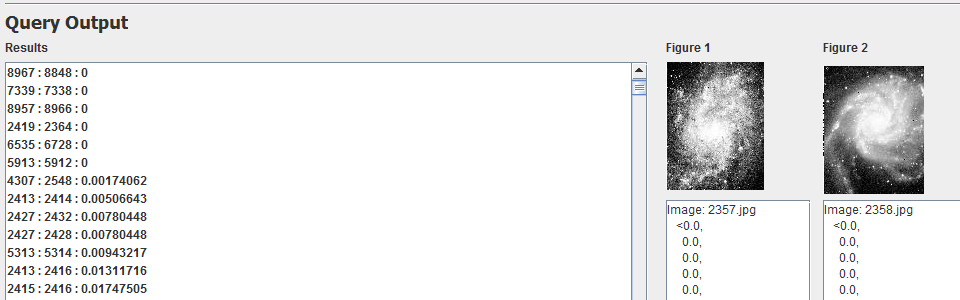
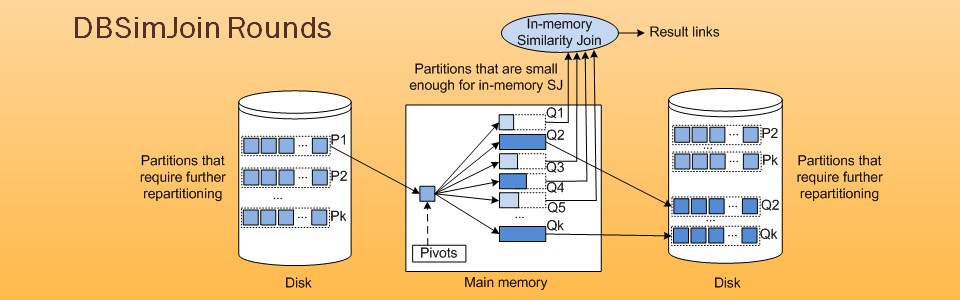
Similarity-aware queries are a very important tool in the field of data management and analysis. This is due to the shifting focus in this field towards dealing with more imprecise and approximate data rather than exact semantics. Data cleaning, data warehousing, sensor networks, marketing analysis, etc. can all benefit greatly from these types of queries. Unfortunately, while work has been done on standalone similarity-aware algorithms, very little has been done on examining the interaction and implementation of these operators inside an actual database system.
The SimDB project aims to implement similarity-aware operators - such as Similarity Group-by and Similarity Join – as first-class database operators and to study their performance and interaction with other conventional and similarity-aware operators.
